Memcached 是一个非常流行的开源免费的高性能分布式缓存系统,基于BSD 开源许可,官方网站是 memcached.org。Memcached 的历史比较悠久,早在2003年就发布了第一版,持续再更新,发展到现在已经非常成熟,其使用开放的通讯协议,客户端只要符合通讯协议,可以使用任何语言实现,目前大多数主流开发语言都支持 Memcached 的 API。Memcached 以及简单轻量、高性能、稳定可靠的特点被各大互联网公司广泛使用,这里面包括 YouTube,Facebook、Twitter 以及国内的BAT 等知名公司,甚至 AWS,Google App Engine 、Microsoft Azure 云服务商也将其包装成基础设施通过 API 对外销售。
Memcached 是一款完全内存型的 key-vlue 缓存中间件,不支持久化存储,当数据达到上限时是会按照 LRU(Least Recently Used —— 最近最少使用)策略清理掉旧数据。Memcached 基于非阻塞的事件驱动架构,使用 libevent 库,可以支持大量的并发请求,按照官方说法,在网络带宽、硬件速度都良好的情况下,Memcached 可以轻松支持每秒 20000+ 的并发请求,即使在速度比较慢的设备上,每秒处理几百个请求也根本不用担心。
Memcached 没有使用传统的 malloc 的内存分配方式,传统方式容易产生内存碎片,降低内存的分配速度。Memcached 而是使用一种 Slab 的分配方式,按照一定尺寸的块(chunk)分配内存。Memcached 首先会将内存按照页(page,默认1M)来分割,并将页按需分配给 Slab 类,分配之后就不会再移动,然后在按照块(chunk)的大小切割再次进行切割,其中 Slab 可以理解为块集合,如图:
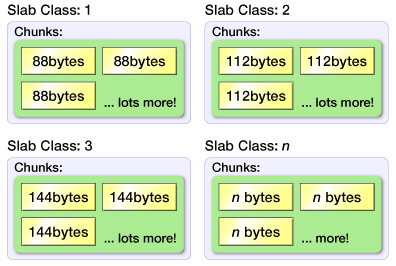
(http://gihyo.jp/dev/feature/01/memcached/0002)
在储存数据是,Memcached 会按照数据的大小选择合适的块来存储,如图:

Slab 类 和块的大小,可以通过 -vv 参数参看查看,比如:
$ ./bin/memcached -vv
slab class 1: chunk size 96 perslab 10922
slab class 2: chunk size 120 perslab 8738
slab class 3: chunk size 152 perslab 6898
slab class 4: chunk size 192 perslab 5461
slab class 5: chunk size 240 perslab 4369
slab class 6: chunk size 304 perslab 3449
slab class 7: chunk size 384 perslab 2730
slab class 8: chunk size 480 perslab 2184
slab class 9: chunk size 600 perslab 1747
slab class 10: chunk size 752 perslab 1394
省略...
比如在 slab class 1 中,每个块的大小是 96字节,那么一个页(1M)可以配成 10922 个块。如果数据的 key+value 有 60 字节,那么这条数据会存储在 slab class 1中,如果,数据有 110 字节,数据会存储在 slab class 2 中,当然显而易见这会造成一定内存空间浪费,Memcached 提供一个启动参数 -f 可以调节块的大小,理想的情况下数据的大小和块的大小一样,当然如合能调到最优,需要你提前对要缓存的数据做一个预判。
Memcached 的安装非常简单,这里就不再赘述,如果想省去源码编译的麻烦,可以使用 bitnami 提供的一键安装包,https://bitnami.com/stack/memcached。
启动 Memcached 命令例如:
$ memcached -d -m 128m -u root -l 127.0.0.1 -p 11200 -c 2048 -P /yourpath/memcached.pid
Memcached 的使用也比较简单,只有限的几个参数,常用参数如下:
-p <num>,TCP 的监听端口,默认是 11211。除了 TPC 以外,Memcached 还支持 UDP协议和 UNIX Socket 方式通信,常用的是 TCP 方式。
-U <num>,UDP 监控端口,默认11211,0 表示关闭。
-s <file>,UNIX Socket 文件路径,这种方式通常是吧 Memcached 当做本地缓存要用,在本机通讯使用 UNIX Socket 方式要比走网络效率要高,页更安全。
-l <addr>,监听的IP地址,如果只允许本机方式,可以设为 127.0.0.1,如果允许远程访问,可以设为 0.0.0.0,如果服务器有多个IP,可以绑定到某一个IP上。另外,也可以在这里直接设置端口号,如 127.0.0.1:8899
-d,以后台守护进程方式启动。
-t, 用来设定用来处理请求的线程数,默认为4,建议不要超过cpu的个数。
-u <username>,以哪个用户身份启动。
-m <num>,指定 Memcached 可以使用的内存大小,以 MB 为单位,默认是 64 MB。
-M,当内存超出预设时进行报错而不是清除内存。
-c <num>,指定最大并发练技术,默认是 1024 。
-v/-vv/-vvv,输出信息的基本,一个v最少,vvv,最详细。
-P <file>,进程 PID 文件,记录当前进程号, 通过这个文件可以用来杀死进程,如 kill `cat /yourpath/memcached.pid`
-f <num>,设置块大小的增长因子,默认是1.25,用户调优,块的会按早1.25的倍数增长长,比如 96,120,152 等
-C, 禁用CAS功能。CAS(check and set)功能可以用来保证数据一致性,但会增加请求的失败率。
-I, 设置页的大小,默认为 1M,该值也是被存储的数据的最大上限。
-B, 设置通讯协议,值为 auto、ascii、binary 之一,默认为自动协商(auto)。
-F, 禁用 flush_all 命令。flush_all 用于清除所有缓存。
Memcached 由于过于简单,软件本身不提供集群功能,多个 Memcached 服务之间相互独立,没有通讯功能,所以需要额外架构设计来使其支持集群功能。一种办法就是通过客户端使用一致性哈希算法实现集群功能,如下图所示,一致性哈希的内容参见上一节的内容:
(补充一个图:TODO)
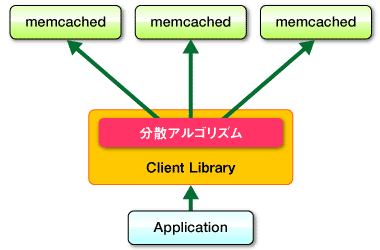
(http://gihyo.jp/dev/feature/01/memcached/0001)
这种方式的好处集群配置完全暴露给客户端,使用哪种一致性哈希策略,连接哪些主机完全有客户端来决定,但会增加开发人员的负担,如果 Memcached 的主机地址写死在应用程序中,一旦某台服务器的宕机,应用程序服务立即响应,会造成服务的古故障,而且不利于服务器的动态水平扩展,尤其对与一些上了规模的公司,Memcached 作为基础服务提供给多个应用使用,服务器需要扩容是,所有相关应用都要跟着修改配置,所以效率非常低下,会造成运维成本的提升,也会带来服务不稳定的风险。下面介绍一种通过Twemproxy 代理代搭建 Memcached 的方法,可以解决上述问题。
(TODO 服务器越多管理起来越困难)
Twemproxy(也叫 Nutcraker) 是一个针对 Memcached 和 Redis 的快速、轻量级的代理软件,由 twitter 公司开源,基于 Apache 2.0 开源许可。Twemproxy 通过和后端服务器保持较少的长连接从而降低整理的连接数,还能通过一致性哈希自动对数据分片,自动踢出失效主机,帮助你对对后端服务器集群的管理。在其内部将接收到的客户端请求和转发给后端服务的请求放在相同的缓冲区,对于服务端返回的数据也是使用相同的方式,实现所谓的“零拷贝”(Zero Copy),从而加速的了代理转发的速度。
下面我们通过实例演示如何使用 Twemproxy 搭建 Memcached 集群:
Twemproxy 的安装:
$ wget https://github.com/twitter/twemproxy/archive/v0.4.1.tar.gz
$ tar -zxvf v0.4.1.tar.gz
$ cd twemproxy-0.4.1/
$ sudo autoreconf -fvi
$ sudo ./configure --prefix=/usr/local/twemproxy
$ sudo make
$ sudo make install
修改 Twemproxy 配置文件,配置文件使用 YAML 格式,默认在 conf/nutcracker.yml 中
# 服务器池名称,可以定制,这里我们命名为,’memcached_pool‘,在一个配置文件中可以制定多个服务器迟,在这里我们仅以一个为例。
#
memcached_pool:
# 服务器监听的地址和端口,这里页可以制定 UNIX Socket 文件额路径。
listen: 0.0.0.0:22121
# 使用哪种哈希算法,目前包括的算法有 md5,crc16,crc32,crc32a,fnv1_64,fnv1a_64,fnv1_32,fnv1a_32,hsieh,murmur,jenkins。
hash: fnv1a_64
# 定义 key 的分布式方式,包括 ketama,modula,和 random 三种。其中 ketama 使用一致性哈希算法。modula 根据哈希值取模,random 表示随机分配,而不管哈希值时什么。一般都会使用 ketama。
distribution: ketama
# 定义哈希标签,一个开始字符和一个结束字符。哈希标签允许使用key的一部字符串来用作一致性哈希的计算,该方法可以让客户端控制数据的存储位置,比如这两个key thread_{1001}_user_rommel 和 thread_{1001}_user_sam 会存储在同一台服务器上。
hash_tag: "{}"
# 和后端缓存服务器通信的超时时间,以毫秒为单位,默认是一直等。
timeout: 400
# Twemproxy 只支持两种缓存软件,这里 true 表示是 redis,false 为Memcached
redis: false
# Twemproxy 进程启动时是否连接所有的服务器,默认为 false
preconnect: true
# 当后端服务器在 server_failure_limit 所规定的次数内连续不可用时是否将其临时踢出,踢出的服务器不在于一致性哈希的计算。
auto_eject_hosts: true
# 连续失败次数,默认为 2,不能为0。
server_failure_limit: 1
# 当 auto_eject_host 为 true 时,该参数设定与被踢出的服务器重连的等待时间,以毫秒为单位,默认 30000毫秒。
server_retry_timeout: 5000
# 设置 TCP 协议中 backlog 参数,用于控制链接队列长度。
backlog: 1024
# Twemproxy 进程和每个后端缓存服务器之间的连接数,默认为1,这样可以保证对同一台服务器数据操的一致性,即所谓的“read my last write”,通常我们保持默认即可。
server_connections: 1
# 定义后端服务器地址,格式为“地址:端口:权重”
servers:
- 192.168.56.101:11211:1
- 192.168.56.102:11211:1
- 192.168.56.103:11211:1
(http://blog.csdn.net/zhaokuner/article/details/23333199)
编写完配置文件之后可以 nutcracker 检查语法
$ nutcracker -c ./conf/nutcracker.yml -t
nutcracker: configuration file './conf/nutcracker.yml' syntax is ok
启动 Twemproxy
$ nutcracker -c ./conf/nutcracker.yml -d
nutcracker 的更多参数:
-t, --test-conf : 测试配置文件的语法
-d, --daemonize : 以守护进程方式启动
-D, --describe-stats : 进程退出是打印状态信息
-v, --verbose=N : 日志日志级别,默认为5,最大为11,做小为0
-o, --output=S : 日式输出文件
-c, --conf-file=S : 配置文件路径 (默认: conf/nutcracker.yml)
-s, --stats-port=N : 状态监听端口 (默认: 22222)
-a, --stats-addr=S : 状态监听服务绑定IP (默认: 0.0.0.0),服务器动以后可以通过 http 方式访问 http://stats-addr:stats-port 查看服务器状态
-i, --stats-interval=N : 监听状态的更新频率 (默认: 30000毫秒)
-p, --pid-file=S : pid 文件位置,用户保存进程号
-m, --mbuf-size=N : mbuf 的块大小,默认16K,最小 512字节,最大16M。
Twemproxy 使用 mbuf 实现零拷贝,mbuf 的大小会对服务器的稳定有一定的影响。对于一个可以分段的请求比如,get key1, key2,在分布式环境下可以分布在不同的主机上,所以会分拆成两个请求 get key1 和 get key2,这样就会消耗4个mbuf,两个用于处理请求,两个用于处理响应,所以对于一个N个分段的请求就需要 2N 个mbuf,而 mbuf 会被重用而不会释放。随意如果 Twemproxy 面对一个1000个客户端链接和100个服务端链接时,就需要消耗 max(1000,100) 2 * mbuf-size 大小的内存,如果客户端请求不分段,会消耗32M内存,如果分10段,则会消耗320M,如果同时处理的是 10000 个请求,则会消耗3.2G内存,如果通过 -m 参数把 mbuf 大小降为 512 字节,则只会消耗 10M 内存。大的 mbuf-size 会提高处理速度,但也会造成内存的膨胀,在面对大并发时(尤其涉及到大量分段操作时)推荐使用更小的 mbuf-size。